Part A
Before starting, I should have understood what inline assembler is. It is assembly code we learned but it is included within a program coded in high level language like C. To understand it more, click the link below.
SPO600: LAB 7A (INLINE ASSEMBLER)
In this lab, I am going to compare the performance of source code provided by Professor. Chris Tyler to code that used for lab 6. And the source code given includes inline assembler, which made the performance faster. First, I changed the sample size in vol.h, and then updated the code to check time. Also, I ran the best performance code used for lab 6, which used using fixed-point.
// vol.h #define SAMPLES 500000000
// vol_simd.c :: volume scaling in C using AArch64 SIMD
// Chris Tyler 2017.11.29
#include
#include
#include
#include
#include "vol.h"
#include
int main() {
int16_t* in; // input array
int16_t* limit; // end of input array
int16_t* out; // output array
clock_t start_t, end_t, total_t;
// these variables will be used in our assembler code, so we're going
// to hand-allocate which register they are placed in
// Q: what is an alternate approach?
register int16_t* in_cursor asm("r20"); // input cursor
register int16_t* out_cursor asm("r21"); // output cursor
register int16_t vol_int asm("r22"); // volume as int16_t
int x; // array interator
int ttl; // array total
in=(int16_t*) calloc(SAMPLES, sizeof(int16_t));
out=(int16_t*) calloc(SAMPLES, sizeof(int16_t));
srand(1);
start_t = clock();
printf("Generating sample data.\n");
for (x = 0; x < SAMPLES; x++) {
in[x] = (rand()%65536)-32768;
}
// --------------------------------------------------------------------
in_cursor = in;
out_cursor = out;
limit = in + SAMPLES ;
// set vol_int to fixed-point representation of 0.5
// Q: should we use 32767 or 32768 in next line? why?
vol_int = (int16_t) (0.5 * 32767.0);
printf("Scaling samples.\n");
// Q: what does it mean to "duplicate" values here?
__asm__ ("dup v1.8h,w22"); // duplicate vol_int into v1.8h
while ( in_cursor < limit ) {
__asm__ (
"ldr q0, [x20],#16 \n\t"
// load eight samples into q0 (v0.8h)
// from in_cursor, and post-increment
// in_cursor by 16 bytes
"sqdmulh v0.8h, v0.8h, v1.8h \n\t"
// multiply each lane in v0 by v1*2
// saturate results
// store upper 16 bits of results into v0
"str q0, [x21],#16 \n\t"
// store eight samples to out_cursor
// post-increment out_cursor by 16 bytes
// Q: what happens if we remove the following
// lines? Why?
: "=r"(in_cursor)
: "r"(limit),"r"(in_cursor),"r"(out_cursor)
);
}
// --------------------------------------------------------------------
printf("Summing samples.\n");
for (x = 0; x < SAMPLES; x++) {
ttl=(ttl+out[x])%1000;
}
end_t = clock();
total_t = (end_t - start_t) / CLOCKS_PER_SEC;
// Q: are the results usable? are they correct?
printf("Result: %d\n", ttl);
printf("Time: %lds\n", total_t);
return 0;
}
The result from the code given was slower than the code used for lab6.
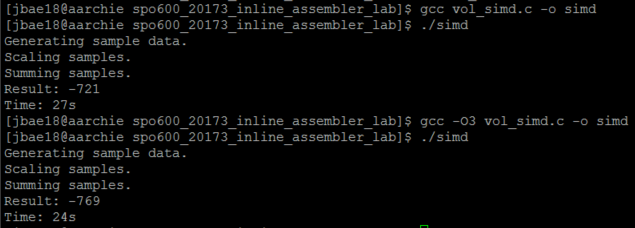
[jbae18@aarchie spo600_20173_inline_assembler_lab]$ ./simd Generating sample data. Scaling samples. Summing samples. Result: -721 Time: 27s
[jbae18@aarchie labs]$ gcc musicV3.c -o m3 [jbae18@aarchie labs]$ ./m3 Time: 25s
When I used flag -O3 for both, the result was 24s and 22s respectively. Now, I will try to answer to the questions from my analysis.
[jbae18@aarchie spo600_20173_inline_assembler_lab]$ gcc -O3 vol_simd.c -o simd [jbae18@aarchie spo600_20173_inline_assembler_lab]$ ./simd Generating sample data. Scaling samples. Summing samples. Result: -769 Time: 24s
[jbae18@aarchie labs]$ gcc -O3 musicV3.c -o m3 [jbae18@aarchie labs]$ ./m3 Time: 22s
Q: What is an alternate approach?
Let the compiler assign register by itself, not given.
Q: Should we use 32767 or 32768 in the next line? why?
Because int16_t has its maximum data , which is 32767.
Q: What does it mean to duplicate values here?
It means the register given, w22, is used to v1.8h.
Q: What happens if we remove the following lines? Why?
Tested after commenting the part. We can compile but cannot run it.
[jbae18@aarchie spo600_20173_inline_assembler_lab]$ ./simd Generating sample data. Scaling samples. Segmentation fault (core dumped)
Q: Are the results usable? Are they correct?
Yes, the results usable and correct.
From this experiment, I learned that the value of sum changed every time I ran it. Also, assembler was affected by build options.

One thought on “SPO600: LAB 7A (INLINE ASSEMBLER)”